Process Reward Models Meet Planning:
Generating Precise and Scalable Datasets for Step-Level Rewards
Abstract
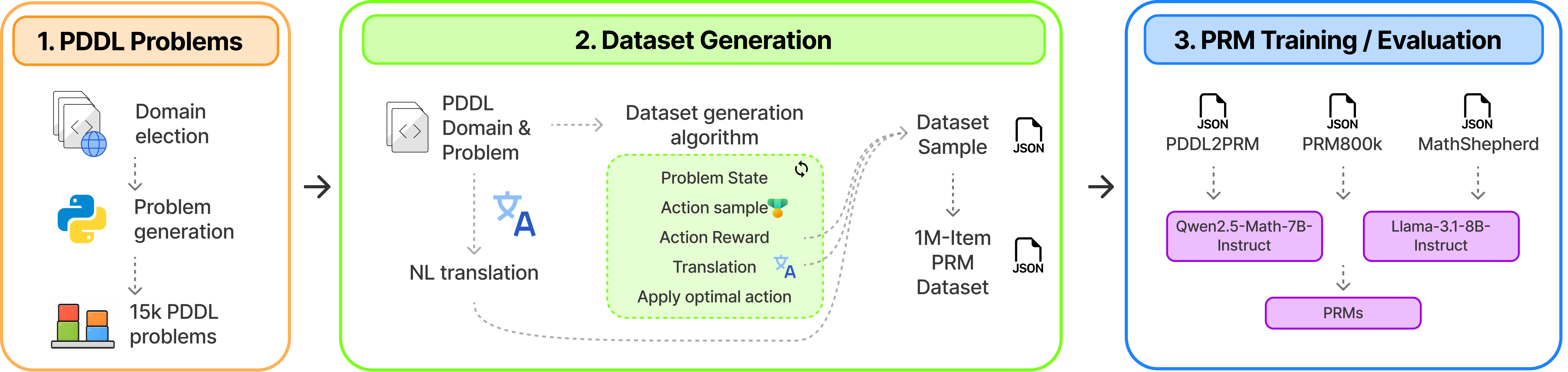
Process Reward Models (PRMs) have emerged as a powerful tool for providing step-level feedback when evaluating the reasoning of Large Language Models (LLMs), which frequently produce chains of thought (CoTs) containing errors even when the final answer is correct. However, existing PRM datasets remain expensive to construct, prone to annotation errors, and predominantly limited to the mathematical domain. This work introduces a novel and scalable approach to PRM dataset generation based on planning logical problems expressed in the Planning Domain Definition Language (PDDL). Using this method, we generate a corpus of approximately one million reasoning steps across various PDDL domains and use it to train PRMs. Experimental results show that augmenting widely-used PRM training datasets with PDDL-derived data yields substantial improvements in both mathematical and non-mathematical reasoning, as demonstrated across multiple benchmarks. These findings indicate that planning problems constitute a scalable and effective resource for generating robust, precise, and fine-grained training data for PRMs, going beyond the classical mathematical sources that dominate this field.
Overview
Citation
@inproceedings{prmsmeetplanning2026,
title={Process Reward Models Meet Planning: Generating Precise and Scalable Datasets for Step-Level Rewards},
author={Pisano, Raffaele and Navigli, Roberto},
booktitle={Proceedings of ACL 2026},
year={2026}
}